

Need help with performance on storage VPS

Hello
I am a customer of @AnthonySmith, trying to setup nextcloud on 'UK STORAGE KVM 4GB' plan.
I have no idea what I am doing wrong but I can't find what's causing my performance to drop as far as the machine going unusable. I am usually far from asking for help on internet forums but I am literally lost on this. The symptoms are basically like this: The machine runs great after a clean boot, nextcloud is smooth (not expecting any miracles here really), ssh works fine, yum/dnf updates are going OK. I leave it running unattended in this state for some time (eg. 10-15hours). After this time when I try to login to the nextcloud interface - sometimes the login page won't even load or it'll take few good minutes to even get page title. I try to login via SSH to the machine - this also hangs for few good minutes, sometimes even refuses to connect. Once I am in the session - typing is very laggy (similar to what you'd see if you had really high latency but mine is around 30-35ms). I expect that the TOP or IOTOP would show me that something is really busy at this point and find the reason for my poor performance but instead:
%Cpu(s): 0,0 us, 0,3 sy, 0,0 ni, 96,7 id, 0,0 wa, 0,7 hi, 1,0 si, 1,3 stMiB Mem : 3781,0 total, 2810,0 free, 531,7 used, 439,4 buff/cacheMiB Swap: 4072,0 total, 4072,0 free, 0,0 used. 3002,3 avail Mem
IOTOP didn't show me anything useful, the sql database wrote ~8MBs to the disk after dozen of minutes which I don't consider dramatic load (maybe I am wrong?).
The current setup is CentOS8, NGINX, PHP-FPM, MariaDB - all from the official+epel repos, Nextcloud version is 17.0.2 - current stable.
I currently didn't setup any cache within nextcloud so it'd be easier to pinpoint issues. Previews generation is limited to 100x100 to lower the load, most apps from nextcloud are disabled.
During last few days I have also tried CentOS7 with rh-php72, MariaDB from the official MariaDB repo, nextcloud with apcu,opcache and redis enabled - but the results were all similar.
From my observation it looks like if everything was going to 'sleep' after some unknown time and I need to wait really long to wake them up. Basically, once I get to the nextcloud page and login - it usually starts to work more or less OK for some time. Similarily - once I wait long enough to get to the machine via SSH - the next login is much faster, same for launching TOP etc.
I have noticed that dnf background service would take a lot of time on CPU and IO so I have disabled the dnf-makecache timer and service - this also didn't help. The nextcloud instance itself is used by me and another member of the family. The data on it is rarely changed.
I had at least one case where once the machine entered this poor performance state I couldn't even reboot it properly - the shutdown took really long and after that - the boot hanged on 'Probing EDD (edd=off to disable) ....'. I forced reboot via the VPS panel and then it worked really smooth for around ~15 hours after which it started to misbehave again ![]()
I am really lost on this so I am kindly asking for any help. Also - I want to make it clear that @AnthonySmith services are really great, I own few other KVMs from his offer and also shared web hosting and they are all great. His service is of top quality and I can't say any bad word about Inception Hosting at all. In fact - I have recommended it to my friends. I am quite sure this is some configuration problem on my end that I just seem to be unable to fix.
Thank you
Also, happy new year to everyone ![]()
Comments
I don't know Centos enough to be able to give suggestions, but I dont read the version of NextCloud, maybe it might help...
It's NextCloud 17.0.2
I'm seeing something similar with debian on my UK Storage KVM. apt-get update takes several minutes with loadavg shooting up to 7 or 8 with nothing else running. No problems on other services. It's not critical for me so I'm waiting until the end of @AnthonySmith's christmas holiday before I send in a ticket.
I am experiencing a quite similar behavior since some time on my UK storage KVM. I am seeing IO wait as high as 74% and 1.5% steal within the last weeks time frame. I suspect the spinning disks which he mentioned to be used there are hitting their limits?
@radmerc
DNF/Centos8: why? come off extraneous software/bleeding edge.
(@Bochi 1.5% steal shouldn't be an issue, that I/O wait sure is though.)
Open a ssh and begin top monitoring, with a 5s interval. Then try logging into Nextcloud
Check your DNS with leafDNS; are you having a TTFB issue? GTMetrix might assist.
What partition layout are you using? Separate /var, /tmp & /home? Nextcloud data in its' own partition?
Notes: I don't have the same service with inception but I do have a LETbox basic storage instance. This is solely for Nextcloud use with webmin & debian 9. I also use this configuration on some dedis. The only reason these don't use Centos 7, is that CWP is a pain to get running with Nextcloud.
lowendinfo.com had no interest.
Forget about OS, use docker
Action and Reaction in history
lowendinfo.com had no interest.
I can't exactly understand what you mean but I trust CentOS 8 to be stable for my needs.
I have it all on single partition + boot. Nextcloud data just lies in different path as suggested by the official docs. Either way the nextcloud part seems really irrelevant in all of this, I'd understand the gateway timeouts between nginx and php-fpm if I loaded it with thousand files for sync (I actually expect that to happen with my config) but the thing is pretty much idling and the problems still occur out of nowhere. In fact I've just tried to connect to the server via SSH again and it took dozens of seconds to even respond with the password prompt and another dozen of seconds for the shell to come up. Loading top was also slow. However, nextcloud web interface seems to work more or less OK atm. but this would conclude with my observation of things acting like if they'd go to sleep - I just kept refreshing the web interface from my phone for most of this time while SSH and other stuff wasn't running. Caching is out of question on my side since I don't use it neither in browser nor on server. Still, I have no real idea about the reasons why things work the way they do. It might be just false assumption either way and matter of right timing.
Also:
load average: 1,32, 0,57, 0,31And a little update after thing settle down:
load average: 0,00, 0,14, 0,22And what happens when I relog via ssh again:
load average: 0,55, 0,32, 0,27@radmerc Can you do a simple dd test?
And see what sort of performance you get for large sequential writes? That machine is advertised as a dedicated CPU core (thread?). Your load average is fine.
Ionswitch.com | High Performance VPS in Seattle and Dallas since 2018
Load average isn't of concern at this point, unlike i/o wait & steal.
Remove DNS resolving from sshd_config, if enabled.
traceroute from your PC to your VPS (may need to open your firewall).
Once, again: GTMetrix on your Nextcloud URL.
lowendinfo.com had no interest.
I'll do the dd tests later - don't know why I didn't think of it, thanks. About the CPU - I'd have to check but as far as I remember it was dedicated CPU core.
I did monitor the wa and st in top earlier and they didn't concern me at all but I did another round again with nextcloud syncing few hundred of small files (which should be the worst case for nextcloud):
%Cpu(s): 3,7 us, 92,7 sy, 0,0 ni, 0,0 id, 0,0 wa, 1,3 hi, 0,7 si, 1,7 st- php-fpm workers going highUseDNS is at default which is 'no'
I have no problems with routing to the machine from my network, I didn't mention it in the first post but I did traceroutes before and went as far as to test access from three different networks with same results
GTMetrix says TTFB is around 481ms.
Unfortunately I don't know if I should consider such short term tests valid at all - especially as everything seems to work more or less OK atm (and i didn't do anything to fix it).
I'll try to get back to it tomorrow.
Nextcloud has a cron that's by default set to run on every page load, which can cause jobs to queue until the next visit. You can change it to a proper linux cronjob every minute etc to keep things running quick.
It's a simple yet easy to overlook possibility.
Get the best deal on your next VPS or Shared/Reseller hosting from RacknerdTracker.com - The original aff garden.
Similar to mine, using Vancouver to a USA VPS.
It'll be interesting to try the same tomorrow, prior to any other contact with your VPS. Perhaps Ant will be feeling a bit better and can investigate from his perspective.
Note: the "wake up" symptom that you describe is similar to a dedi in the States, that I run Proxmox on. As it's for my own use, I haven't investigated the cause and doesn't appear to be as drastic as your experience.
lowendinfo.com had no interest.
Run vmstat 1 in tmux/screen session. Close that terminal by clicking X
Check that terminal's history when you re-login tomorrow.
Sounds like something is getting swapped out to disk either on Guest OR Hypervisor.
See which it is by checking history of the si vs bi columns in vmstat output. (last 30 secs history)
If it's large values of bi, send host a ticket with output/screenshot.
If it's lots of si, reduce vm.swappiness to 1 , and repeat diagnostics after 6-18 hrs.
Considering guest has 4GB ram, my gut thinks your host will have to find the io bottleneck on the hypervisor.
Hope Ant's feeling better . He should be able to sort it out satisfactorily.
My experience was with these "storage deals", I had a lot of I/O peaks.
Which made it impossible for some applications to run, some requests hang multiple seconds.
There are just meant, to dump files and run, not run applications on it.
Do you have anything in syslog?
Free NAT KVM | Free NAT LXC
What actual impact is it having, I see you said the performance makes it unusable, but what specifically is unusable? The web ui?
I am asking because I have had a number of people complain and when it all gets down to brass tacks it is because they bought it to run as not a storage service, rather than needed a cheap kvm and lots of storage to go with it.
In every scp, wget, ftp, rsync, test it has been able to near enough max out the link, that is what these servers are for and an extra confirmation is made that people understand this during checkout.
I really have no interest in dd test results for this service, at times it will be shocking, but will have no bearing any real world intended use.
The thing causing more issues than anything on this service is people using it not as intended, I have had someone complaining that their office emails are not running great since moving to it, they had about 300GB worth of email running on imap connected to multiple outlook clients and some funky browser based intranet software on top.
Few people have complained about nextcloud, I have always said you are welcome to install it but don’t expect the experience to be great, the server. Is running on slow high capacity spinners in raid 5 it is about as slow as raid can get.
It is for storage, if you have an issue with storage, let me know, not a synthetic one, a real one an issue with database reliant software is only going to result in a quote for a faster storage solution at around 5x the price.
https://inceptionhosting.com
Please do not use the PM system here for Inception Hosting support issues.
I've got to say that my backup jobs are all running fine so no more complaints from me.
@AnthonySmith
Hello. It is not my intent to make a complaint against the service, I am sorry if you took it as so. I am just trying to figure out the culprints on my VPS, particulary in my setup, and trying to adjust it to the best possible. When I purchased the VPS I was expecting that running services like nextcloud would be slow due to the 'storage' nature of this (and I've tried to make it clear in the first post by saying that I don't expect miracles in this term).
My results are somewhat semi-random. As for the question if the web ui is slow - just right now I had this situation where the nextcloud login page would load without problems and the client synced state really fast - but I had problems connecting via SSH to the server. Even weirdier for me was that once I got into the ssh session and tried to open the 'top', my session would be 'closed by remote host.' out of nowhere. All this while pings are still on around ~33ms.
I am currently stopping all the web related services - it takes dozens of seconds for each one to stop.
Performing
yum update- I am counting it via the timer in my phone - over 4 minutes and I didn't get a single line of reply from the command yet. After some time longer I got first line of update (date of last metadata check), at this moment - my pings went up to time=11558 until they hitDestination Host Unreachable, but a moment later they got back to the 33ms. The yum update is still working - over 6 minutes. Around 7 minutes and 50 seconds - the yum update is done (nothing to do). Now to get back to the observations from my first post - I kind of expect that if I reboot the machine the yum update will be going smooth. I had this happen to me already when I rebooted machine previously after having similar issue.And similarily, running
yum updatesubsequently after it completes the first time - it works OK. These are my observations that are hard for me to understand, unless it comes down to disk data seeking / caching which is the only sane explanation that comes to my mind, tho I couldn't observe any drama on the top / iotop previously and that's why I am asking for any advice.Edit:
As for the wget tests - Do you have any test links that I could use and consider reliable?
My experience so far for the few I found from google is just as random with downloads starting high until they hit even as low as ~65KBps and then it becomes unpredictable with speeds jumping from 200-400KBps to 1-2MBps. I can try to download all the files fully to see the average results if that's of any help.
Edit2:
I am trying to download test file from ovh.net fully. It had one retry already (the first part was 717 KB/s), the other part is still downloading. Now could anyone explain this to me:
%Cpu(s): 0,3 us, 95,7 sy, 0,0 ni, 0,0 id, 0,0 wa, 1,7 hi, 0,7 si, 1,7 stPID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND3993 root 20 0 269904 6084 5468 R 94,7 0,2 20:36.57 wgetI've never seen wget take so much CPU...
Edit3:
2020-01-02 21:07:43 (428 KB/s)10Gb.dat' [1250000000/1250000000]/etc/resolv.conf?
Which DNS provider are you using for the domain?
Is your ssh slowness there, whether you use IP or domain name?
Are you bound to the correct gateway? I presume you're using a static IP.
Which firewall and do things improve dramatically if temporarily disabled?
Are any of the system logs getting saturated?
lowendinfo.com had no interest.
The domain's NS are pointed to the Inception Hosting's shared hosting from where I manage zone entries. This one is actually a subdomain of the domain which points to a different, non-storage VPS. I have no problems connecting to the other VPS from my home network, I actually did a small test on the other VPS to download the same test file and it averaged 30,4MB/s. The DNS on my end is basically what comes from my ISP but I have no problem resolving these domains from my end.
The DNS for the VPS are set to 8.8.8.8, 8.8.4.4 (Google Public DNS). I assume i didn't mess up the gateway but frankly have no idea how to verify it.
As for the server firewall - selinux + firewalld. I didn't do any tests with these disabled yet.
As for the slowness of SSH it seems irrelevant - in fact, the machine had a moment of going blazing fast, I could login via ssh immediately and the wget session was going over 20MBps but the speed dropped sometime later. Then, after some time it had another such moment and went over 80MBps but again it slowed down after some time.
It looks like when the wget speed drops it sometimes also takes longer for me to get into SSH session if I open another one in next terminal. And I just had 3 retries on wget during the download of the same file as before from ovh.net. Still the way things work faster at one moment and slower at another just looks really weird to me.
Temporarily switch to DHCP?
These should match your static assignment.
What size is /var/log/messages? A "tail -f" on the file might give clues, during the problem times; I suspect it'll be filling up too quickly though.
lowendinfo.com had no interest.
@radmerc - in addition to the suggestion from @vimalware you might also find
atopto be a convenient tool for logging system resource use. I would also be looking atmtr(or similar network quality diagnostics) to help confirm or deny issues with connectivity.In general - if you don't know what you're doing then it might be a good idea to simplify your system as much as possiple. Be methodical, test assumptions, and take notes. Start with the basics - then add application components until something breaks.
HS4LIFE (+ (* 3 4) (* 5 6))
@AlwaysSkint
I set the gateway, ip etc. as static but exactly according to what I got from DHCP during setup. I was thinking that perhaps there is some other way to verify if the information from the DHCP was correct that I don't know of.
I can also totally confirm at this point that reaching SSH either via IP or the Domain makes no difference. To say even more, I had the server rebooted yesterday, stopped nginx, php-fpm and the mariadb services and the machine was just idling in this state after I completed the wget tests. I just came back home and tried to login via SSH and again - it took really long to respond, just as I've seen happen before, all this while connection seemed stable at ~34ms.
I use the default journald so in my case it's more like
journalctl -f -n 100to see last n lines + live update. The only interesting part is the one apparently connected with my observed SSH long response -pam_systemd(sshd:session): Failed to create session: Connection timed out@uptime
It's not exactly that I don't know what I am doing but I don't want to make any assumptions at this point that I am doing things right - I've tried to fix this and failed.
As for the system - I don't think I can simplify this much more, I stopped all the extra services and still had a basic problem of opening SSH session after the server was idling for some time. Don't think the few extra php, nginx and mysql packages would cause so much trouble as they aren't executed atm. The install is the 'minimal' of CentOS8. Even the dnf-makecache is disabled at this point to lower the load.
I'll try to log the system resource usage later to see if I can take any info from it, thank you.
Update:
After another (faster) ssh login I got some other errors:
pam_systemd(sshd:session): Failed to create session: Start job for unit user-0.slice failed with 'canceled'and few instances of:
Failed to connect to API bus: Connection refusedAfter that I did another ssh login (even more faster) and had no extra errors.
I will run up a test VPS on the same node, and do some testing here.
https://inceptionhosting.com
Please do not use the PM system here for Inception Hosting support issues.
@AnthonySmith
Thank you. I really appreciate your help.
@uptime
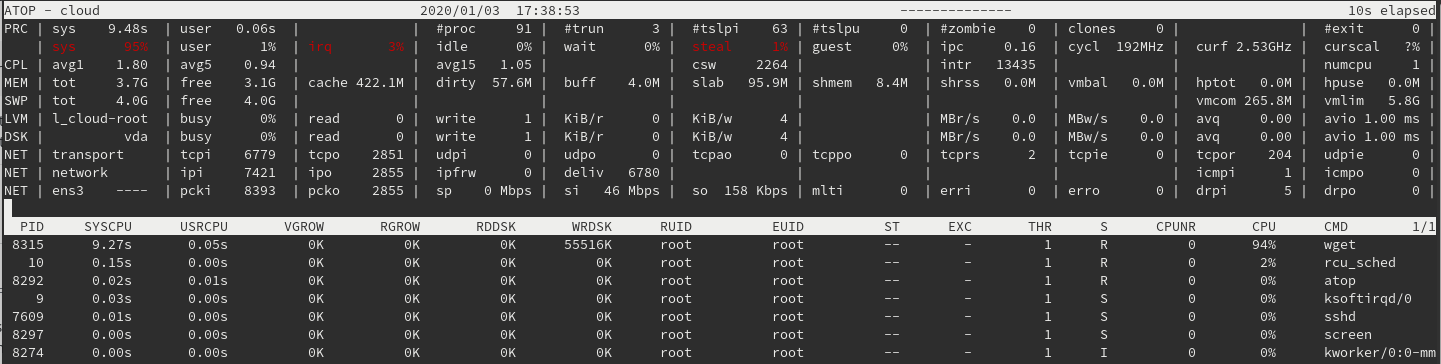
This is what happens when I run wget, trying to download the test file from ovh.net. At this point the machine gets a bit unresponsive. Download speed varies between 100KBps to 1MBps atm.
Update:
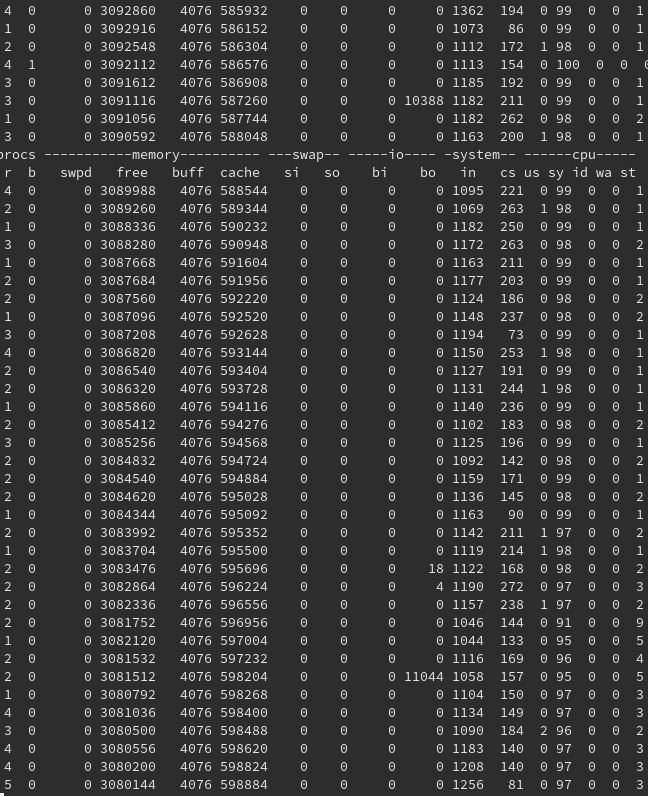
vmstat results
hello again @radmerc - have you looked at
mtryet ...?HS4LIFE (+ (* 3 4) (* 5 6))
I really cant explain that, I am seeing some variable results but nothing even close to that.
I will PM you with the login details of the tiny little 512mb test VPS above on the same node so you can check yourself.
https://inceptionhosting.com
Please do not use the PM system here for Inception Hosting support issues.
I would suggest booting it in to rescue mode and see if you get the same issues.
I appreciate this node will never win performance of the year awards for speed or consistency but what you are seeing is very odd and not typical, I suspect you may need to start disabling things selinux for example and start rolling stuff back, failing that you might be better off just getting cheap dedi, I can arrange a pro rated refund for you if you cant find the cause.
if you are getting dropped off the ssh session on the test VM and I am not then I think perhaps you have some local issues combined with some software issues and possibly dare I say some expectation issues.
It is fine by the way this has not annoyed me at all, sorry if it seemed that way, I just have to take some things with a pinch of salt, you would not believe how many "I know its a storage VPS but..." tickets I get for people trying to run game servers, full web UI's, docker setups, 1 guy was even trying to run a small windows server DC/exchange setup and complaining about how long windows updates took.
With all that said I will look to provision more storage solutions fairly soon and have some ideas to re-balance this one out a bit as I am seeing a little bit more variation than I would like.
https://inceptionhosting.com
Please do not use the PM system here for Inception Hosting support issues.
@AnthonySmith")
My results against 100MBps files are sometimes similar but things change drastically if I let the download run for more than few seconds. My assumption on this was that possibly the things are buffered into ram before they get written to disk so the speed on the 100MB file is just so much different. As for the cheap dedi option - I had it when I made the choice to purchase this VPS and I still regard it as the right choice because I trust you as quality provider and this isn't going to change really in the near time. I do administrate a totally different kind of networks on everyday basis as my work but still it's only so natural for me that I'd try to fix this thing rather than change the server and call it a day
And still the results on your test machine are just so much different from mine:

@uptime

I put a big checklist on the order process that clearly mentions, this is for storage only. Still endup with the same -_-
Nexus Bytes Ryzen Powered NVMe VPS | NYC|Miami|LA|London|Netherlands| Singapore|Tokyo
Storage VPS | LiteSpeed Powered Web Hosting + SSH access | Switcher Special |