@AlwaysSkint said: @Virmach - my fallback secondary server is now working again. The Ryzen Fix IP function did the trick. Phew!
One less thing on your plate. Like that will make a difference!
I've had same issue after migration that some other VPS uses same IP and there are no Ryzen IP fix available at NYCB018. So I have fast Ryzen idler with semiworking network
@AlwaysSkint said: @Virmach - my fallback secondary server is now working again. The Ryzen Fix IP function did the trick. Phew!
One less thing on your plate. Like that will make a difference!
I've had same issue after migration that some other VPS uses same IP and there are no Ryzen IP fix available at NYCB018. So I have fast Ryzen idler with semiworking network
I've gone down these dozens of times at this point and checked for broken IP assignments, looks like I missed one on NYCB018 because I'm semi-dyslexic and it was .212 instead of .221 on a single VM. I've corrected that one now.
Anyone know if CC Buffalo is on some IP blacklists? I have trouble reaching my server there from Comcast where I am right now, but it works fine from just about everywhere else. One person has been able to reproduce the issue from another location on Cox network. The server itself is fine afaict. I have not yet had the energy to compare packet traces at both ends, but will do that tomorrow. This is trés weird.
@willie said: Anyone know if CC Buffalo is on some IP blacklists?
I have normally found over the years that most/almost all CC IPs are on uceprotect.net & many are on barracudacentral.org.
That said, anybody who blocks based on uceprotect.net is not helping anybody IMO.
You can check your IP here just put your IP in the search box and then click the RBL tab.
I got lucky with SJCZ004. After about 20 reboots and messing with the BIOS, when I finally gave up and was going to try recovering data, I selected virtual disk on BIOS and it booted into the OS instead (???) seems like it just wants to do the opposite of everything I tried.
Anyway, something's definitely wrong with it and it was just luck that it even powered on into the BIOS. We're short on servers but I don't see any reason for it to crash so soon, last time it was related to the network reconfiguration, it's been so long I don't remember, but wee should have a lot more servers up soon in the next few days and we'll evaluate an emergency migration at that time.
Huge shoutout to remote hands again for doing literally nothing until the server decided to spontaneously boot itself up. (I know they weren't involved because BMC keeps track of power events, aka, no power button press.)
There's been a lot of cases of people doing their own network configurations due to issues with reconfigure button, but then they set the IP address to the node's main IP or a random IP in the subnet. This is considered IP stealing/network abuse, so I don't know if I have to provide a PSA here but definitely only use the IP address assigned to you. We've had some issues with the anti-IP theft script which uses ebtables so had to disable it on a lot of nodes but this doesn't mean you're allowed to use an IP address you're not paying for/not part of your service. You will be suspended and while I understand in some cases it's just a mistake, we're going to be relatively strict depending on the scenario it caused. With that said, one of these cases pretty much caused SJCZ004 to have problems with the initial configuration and indirectly led to this long outage.
Some other updates:
I've done some limited testing of re-enabling IP security tools after the VLAN splits, and it looks like it's able to run properly at least on some servers, so we're going to focus on fixing these slowly to avoid further problems caused by the IP stealing. This should at least fix a small percentage of those services unable to use their IP as it's possible someone else is using it. Rare but possible.
DALZ009 & DALZ010 are resembling the issue we've had with that board / chassis / CPU / heatsink combo where the clamp down on the CPU is weak and during shipping the CPU gets slightly "lifted" causing it to stick to the heatsink. Usually a CPU re-seat will fix this but the problem is AM4 has the pins on the CPU and if it's not removed properly by a good tech, they could easily damage the CPU and make it worse. So we're shipping in new CPUs and hopefully scheduling it with non-DC techs.
ATLZ007 has a similar issue to SJCZ004 at this time, but not necessarily the same cause, just the same endpoint. I'm attempting to fix it in the same way but it looks like it might actually be functioning more as expected so I'm attempting boot repair.
These nodes are still being looked into but have a problem that's either waiting on DC hands or difficult to identify/complete at the time:
@willie said:
Anyone know if CC Buffalo is on some IP blacklists? I have trouble reaching my server there from Comcast where I am right now, but it works fine from just about everywhere else. One person has been able to reproduce the issue from another location on Cox network. The server itself is fine afaict. I have not yet had the energy to compare packet traces at both ends, but will do that tomorrow. This is trés weird.
This is one of the things where I don't even think it's their fault but they're on a blacklist UCEPROTECT which as @FrankZ mentioned should not be trusted but for some reason it's "industry standard" for a bunch of lazy sys admins to use it. I guess by literally having infinite false positives, it gets their job done of also happening to block some malicious people.
The people that maintain the blacklist essentially extort you for money, and easily put hundreds of thousands of IP addresses on their "3" list I believe, just for a few dozen IP addresses on it being marked as malicious, and then some oblivious companies use this list instead of at the very least using their "2" list which is more specific. Again, they might as well just block a few million IP addresses randomly and they'd achieve the same results.
Yo @Virmach : a wee heads-up in that there's an imminent transfer request coming. Standard Ticket to Billing?
[$/£ exchange rate is killing me, just now. ]
They had the LAN port plugged in as dedicated IPMI on the switch we use for IPMI, and labeled it as a port on the main switch when it wasn't. Took a fair bit of detective work to find since the whole setup is a mess at this point. I'm probably going to have to go down to New York and fix it one day and make it neat, they never followed initial rack instructions and just put everything in randomly basically.
@AlwaysSkint said:
Yo @Virmach : a wee heads-up in that there's an imminent transfer request coming. Standard Ticket to Billing?
[$/£ exchange rate is killing me, just now. ]
P.S.Yessum, UCEProtect scam is a real PITA!
I haven't been billing for these recently but they also take an outrageous amount of time to complete, so a fair bit of warning. This is one of the things I've tried and failed to fix over the last two years. Maybe we'll finally have time for reworking the process but until then you can realistically expect to wait weeks if not longer.
Yes, standard ticket to wherever and it'll get marked as logistical support by us.
@AlwaysSkint said:
(( Ahh, are you sending this equipment with colour coded ports and matching cables? "You put the blue one here.." Square peg; round hole. ))
Normally this would be a good idea, but I don't think this would work for VirMach as I expect he would get his work order assigned to the only color blind tech.
@VirMach said:
There's been a lot of cases of people doing their own network configurations due to issues with reconfigure button, but then they set the IP address to the node's main IP or a random IP in the subnet. This is considered IP stealing/network abuse, so I don't know if I have to provide a PSA here but definitely only use the IP address assigned to you. We've had some issues with the anti-IP theft script which uses ebtables so had to disable it on a lot of nodes but this doesn't mean you're allowed to use an IP address you're not paying for/not part of your service. You will be suspended and while I understand in some cases it's just a mistake, we're going to be relatively strict depending on the scenario it caused. With that said, one of these cases pretty much caused SJCZ004 to have problems with the initial configuration and indirectly led to this long outage.
Two weeks ago, I noticed an IP change when I invoked sudo reboot.
I suppose the IP renumbering occurred prior to my reboot, but my OS didn't pick it up until it reboots.
I have DHCP client, but the DHCP server seems to give out very long leases (many years).
Consequently, in the period between IP renumbering and my reboot, my OS could be using some else's IP address.
Now, if you need to renumber IP assignment, your should reduce DHCP lease duration.
Otherwise, it's not my fault of using someone else's IP address for a long time.
They had the LAN port plugged in as dedicated IPMI on the switch we use for IPMI, and labeled it as a port on the main switch when it wasn't. Took a fair bit of detective work to find since the whole setup is a mess at this point. I'm probably going to have to go down to New York and fix it one day and make it neat, they never followed initial rack instructions and just put everything in randomly basically.
how much are DC hands paid? i would like to take up as summer job. seems like no experience necessary
@AlwaysSkint said:
DHCP for servers is a bloody silly idea, IMHumbleO. (I know, it makes auto-deployment easier!)
I keep DHCP enabled so that the provider can renumber IP addresses if they want; this also allows the service to come up after migration to a different location upon my request. I shouldn't be guilty of "network abuse" if the provider sets improper DHCP lease duration which causes my OS to keep using an IP address that has been unassigned from my service.
So far, four providers renumbered IP address on my services: SecureDragon, AlphaRacks, WebHorizon, VirMach.
Among those, VirMach was the only provider that renumbered IP address without sending prior notice.
If they plan to do so regularly, I may need to setup more scripts to automatically adjust DNS records and such.
@AlwaysSkint said: @Virmach - my fallback secondary server is now working again. The Ryzen Fix IP function did the trick. Phew!
One less thing on your plate. Like that will make a difference!
I've had same issue after migration that some other VPS uses same IP and there are no Ryzen IP fix available at NYCB018. So I have fast Ryzen idler with semiworking network
I've gone down these dozens of times at this point and checked for broken IP assignments, looks like I missed one on NYCB018 because I'm semi-dyslexic and it was .212 instead of .221 on a single VM. I've corrected that one now.
Mine is .232 and when its used some other server, route goes somewhere else than NYCB018 but its happening quite often
@AlwaysSkint said:
(( Ahh, are you sending this equipment with colour coded ports and matching cables? "You put the blue one here.." Square peg; round hole. ))
Normally this would be a good idea, but I don't think this would work for VirMach as I expect he would get his work order assigned to the only color blind tech.
All labeling ever did for us is cause MORE problems so I stopped doing it.
Example A:
Nothing is labeled.
Techs set it up how they want, and maybe communicate it correctly if we're lucky.
Tech may be able to follow instructions for something in relation to RU9.
Example B:
Everything is labeled.
Techs set it up how they want, and maybe communicate it correctly if we're lucky.
Tech gets confused because RU9 server is called "014" on the label.
@AlwaysSkint said: @Virmach - my fallback secondary server is now working again. The Ryzen Fix IP function did the trick. Phew!
One less thing on your plate. Like that will make a difference!
I've had same issue after migration that some other VPS uses same IP and there are no Ryzen IP fix available at NYCB018. So I have fast Ryzen idler with semiworking network
I've gone down these dozens of times at this point and checked for broken IP assignments, looks like I missed one on NYCB018 because I'm semi-dyslexic and it was .212 instead of .221 on a single VM. I've corrected that one now.
Mine is .232 and when its used some other server, route goes somewhere else than NYCB018 but its happening quite often
Yeah, possibly IP conflict. Enabled protection on it. Reconfigure and try again. If it doesn't work, let me know. This could also potentially knock out the entire network for NYCB018 if we're extremely unlucky so I'll check back in 10 minutes.
@VirMach said:
Yeah, possibly IP conflict. Enabled protection on it. Reconfigure and try again. If it doesn't work, let me know. This could also potentially knock out the entire network for NYCB018 if we're extremely unlucky so I'll check back in 10 minutes.
Done and seems work atleast for now. Hopefully net uptime has now better stats, thanks!
@cybertech said:
how much are DC hands paid? i would like to take up as summer job. seems like no experience necessary
With Virmach's recent experiences, seems like no braincells to rub together are needed in some of these companies. I hope he's planning on going back over updates like these and documenting them all to the DC. Or beating them with the paperwork and contracts until they have a braincell fire. Something.
I'd have been roasted over a firepit if i did any of the things he's had done / not done, let alone any combo of them from one DC alone.
If I wasn't Canadian and really not wanting to travel still, I'd say Virmach hire me and I'll just fly around the US going DC to DC as your remote hands for a while lol I've got a bunch of related knowledge, but even if I turned off my brain and just did exactly what was asked, it would be smoother for everyone
Wanted to ask what is wrong with FFME001 as my hetrixtools does not complain...
But then I tried to login as root and it did not allow me (???????????!?!?!? I know my password!)... so I decided to go to panel and I see it's dead (?)
@AlwaysSkint said: @Virmach - my fallback secondary server is now working again. The Ryzen Fix IP function did the trick. Phew!
One less thing on your plate. Like that will make a difference!
I've had same issue after migration that some other VPS uses same IP and there are no Ryzen IP fix available at NYCB018. So I have fast Ryzen idler with semiworking network
I've gone down these dozens of times at this point and checked for broken IP assignments, looks like I missed one on NYCB018 because I'm semi-dyslexic and it was .212 instead of .221 on a single VM. I've corrected that one now.
Mine is .232 and when its used some other server, route goes somewhere else than NYCB018 but its happening quite often
They had the LAN port plugged in as dedicated IPMI on the switch we use for IPMI, and labeled it as a port on the main switch when it wasn't. Took a fair bit of detective work to find since the whole setup is a mess at this point. I'm probably going to have to go down to New York and fix it one day and make it neat, they never followed initial rack instructions and just put everything in randomly basically.
how much are DC hands paid? i would like to take up as summer job. seems like no experience necessary
It's actually a pretty hilarious paradox. They keep raising the rates, reducing the level of service they provide, and I highly doubt it translates over to the hands getting paid much. From what I've seen they basically end up making around 10-20% of the hourly rate you get charged. To be fair though I also assume once you add in benefits, all the dead hours where they still need to be paid, and I'd imagine some level of liability insurance, or possibly sub-contracting, it probably somehow ends up leaving thin margins still.
The part I still don't understand though is the reduction of the level of service AND raising prices astronomically. Basically, at least one of the datacenters raised their rate by like let's say +50% and then they updated their guidelines to where within that timeframe you have to pay for, they'll only do a list of 5 different tasks and that's it. Tasks that definitely take way less than the hour minimum. So once you take that into account you might end up paying $100-200 for a button press and even then they still struggle to do it, so why not just hire more people if the demand is so high? It's not like they're hiring experienced people anyway if they're also unable to do anything above a button press.
@Jab said: Wanted to ask what is wrong with FFME001 as my hetrixtools does not complain...
Haven't been able to look into that one, I've been putting it off/lower on the priority list because I noticed the same thing, it only appears to be a panel issue. It could be the following:
Getting blocked by SolusVM
Wrong configuration settings (highly unlikely as it previously worked)
@VirMach said:
Yeah, possibly IP conflict. Enabled protection on it. Reconfigure and try again. If it doesn't work, let me know. This could also potentially knock out the entire network for NYCB018 if we're extremely unlucky so I'll check back in 10 minutes.
Done and seems work atleast for now. Hopefully net uptime has now better stats, thanks!
@VirMach said:
Yeah, possibly IP conflict. Enabled protection on it. Reconfigure and try again. If it doesn't work, let me know. This could also potentially knock out the entire network for NYCB018 if we're extremely unlucky so I'll check back in 10 minutes.
Done and seems work atleast for now. Hopefully net uptime has now better stats, thanks!
It didn't help, network still going up'n'down
Message me the IP, I want to make sure it's not a node-wide issue.
@VirMach i cannot access service details page of my vps since a week now i always get timed out errors i forgot the new ip and just want to see the ip address of my vps if that's still active what to do?, Also is there any way to reset/check my username so that I can see if ip address there , i always accessed pannel from services detail page which auto logged me in so don't know my user name please help
@VirMach said:
Yeah, possibly IP conflict. Enabled protection on it. Reconfigure and try again. If it doesn't work, let me know. This could also potentially knock out the entire network for NYCB018 if we're extremely unlucky so I'll check back in 10 minutes.
Done and seems work atleast for now. Hopefully net uptime has now better stats, thanks!
It didn't help, network still going up'n'down
Message me the IP, I want to make sure it's not a node-wide issue.
Done, not sure tho if its nodewide since it seems to go to different node when its not working on my server


Comments
I've had same issue after migration that some other VPS uses same IP and there are no Ryzen IP fix available at NYCB018. So I have fast Ryzen idler with semiworking network
Hmm, not a good sign for me, where I'm missing the two additional IPs. Nearly as bad as one being 'stolen'.")
lowendinfo.com had no interest.
I need a vps around $5/year, who can push one for me.
I've gone down these dozens of times at this point and checked for broken IP assignments, looks like I missed one on NYCB018 because I'm semi-dyslexic and it was .212 instead of .221 on a single VM. I've corrected that one now.
Anyone know if CC Buffalo is on some IP blacklists? I have trouble reaching my server there from Comcast where I am right now, but it works fine from just about everywhere else. One person has been able to reproduce the issue from another location on Cox network. The server itself is fine afaict. I have not yet had the energy to compare packet traces at both ends, but will do that tomorrow. This is trés weird.
I have normally found over the years that most/almost all CC IPs are on uceprotect.net & many are on barracudacentral.org.
That said, anybody who blocks based on uceprotect.net is not helping anybody IMO.
You can check your IP here just put your IP in the search box and then click the RBL tab.
Certainement qui est en droit de vous rendre absurde, est en droit de vous rendre injuste - Voltaire
I got lucky with SJCZ004. After about 20 reboots and messing with the BIOS, when I finally gave up and was going to try recovering data, I selected virtual disk on BIOS and it booted into the OS instead (???) seems like it just wants to do the opposite of everything I tried.
Anyway, something's definitely wrong with it and it was just luck that it even powered on into the BIOS. We're short on servers but I don't see any reason for it to crash so soon, last time it was related to the network reconfiguration, it's been so long I don't remember, but wee should have a lot more servers up soon in the next few days and we'll evaluate an emergency migration at that time.
Huge shoutout to remote hands again for doing literally nothing until the server decided to spontaneously boot itself up. (I know they weren't involved because BMC keeps track of power events, aka, no power button press.)
There's been a lot of cases of people doing their own network configurations due to issues with reconfigure button, but then they set the IP address to the node's main IP or a random IP in the subnet. This is considered IP stealing/network abuse, so I don't know if I have to provide a PSA here but definitely only use the IP address assigned to you. We've had some issues with the anti-IP theft script which uses ebtables so had to disable it on a lot of nodes but this doesn't mean you're allowed to use an IP address you're not paying for/not part of your service. You will be suspended and while I understand in some cases it's just a mistake, we're going to be relatively strict depending on the scenario it caused. With that said, one of these cases pretty much caused SJCZ004 to have problems with the initial configuration and indirectly led to this long outage.
Some other updates:
These nodes are still being looked into but have a problem that's either waiting on DC hands or difficult to identify/complete at the time:
This is one of the things where I don't even think it's their fault but they're on a blacklist UCEPROTECT which as @FrankZ mentioned should not be trusted but for some reason it's "industry standard" for a bunch of lazy sys admins to use it. I guess by literally having infinite false positives, it gets their job done of also happening to block some malicious people.
The people that maintain the blacklist essentially extort you for money, and easily put hundreds of thousands of IP addresses on their "3" list I believe, just for a few dozen IP addresses on it being marked as malicious, and then some oblivious companies use this list instead of at the very least using their "2" list which is more specific. Again, they might as well just block a few million IP addresses randomly and they'd achieve the same results.
Yo @Virmach : a wee heads-up in that there's an imminent transfer request coming. Standard Ticket to Billing? ]
]
[$/£ exchange rate is killing me, just now.
P.S.Yessum, UCEProtect scam is a real PITA!
lowendinfo.com had no interest.
Finally fixed NYCB036.
They had the LAN port plugged in as dedicated IPMI on the switch we use for IPMI, and labeled it as a port on the main switch when it wasn't. Took a fair bit of detective work to find since the whole setup is a mess at this point. I'm probably going to have to go down to New York and fix it one day and make it neat, they never followed initial rack instructions and just put everything in randomly basically.
I haven't been billing for these recently but they also take an outrageous amount of time to complete, so a fair bit of warning. This is one of the things I've tried and failed to fix over the last two years. Maybe we'll finally have time for reworking the process but until then you can realistically expect to wait weeks if not longer.
Yes, standard ticket to wherever and it'll get marked as logistical support by us.
If you want something done..
[Alternate]
Can't get the staff these days.
(( Ahh, are you sending this equipment with colour coded ports and matching cables? "You put the blue one here.." Square peg; round hole. ))
lowendinfo.com had no interest.
and ATL-Z007 seem back as well.
Normally this would be a good idea, but I don't think this would work for VirMach as I expect he would get his work order assigned to the only color blind tech.
Certainement qui est en droit de vous rendre absurde, est en droit de vous rendre injuste - Voltaire
I'll second that. "Hmm, shall I wait before switching it back as the secondary nameserver?" i'll see how my day goes.")
((No green & blue cables in the same batch!!!))
lowendinfo.com had no interest.
Two weeks ago, I noticed an IP change when I invoked
sudo reboot.I suppose the IP renumbering occurred prior to my reboot, but my OS didn't pick it up until it reboots.
I have DHCP client, but the DHCP server seems to give out very long leases (many years).
Consequently, in the period between IP renumbering and my reboot, my OS could be using some else's IP address.
Now, if you need to renumber IP assignment, your should reduce DHCP lease duration.
Otherwise, it's not my fault of using someone else's IP address for a long time.
Original incident log:
https://lowendspirit.com/discussion/comment/92125/#Comment_92125
DHCP for servers is a bloody silly idea, IMHumbleO. (I know, it makes auto-deployment easier!)
lowendinfo.com had no interest.
how much are DC hands paid? i would like to take up as summer job. seems like no experience necessary
I bench YABS 24/7/365 unless it's a leap year.
@VirMach
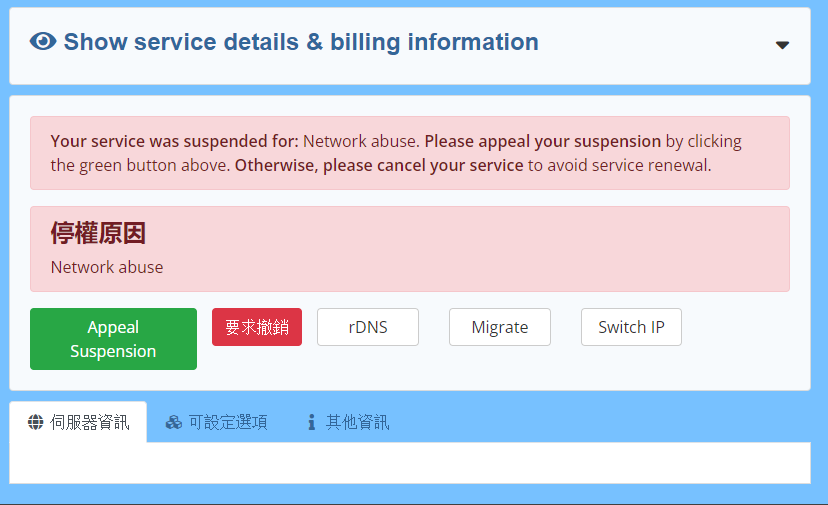
what happened? I can't use it. How can it become a network abuse?SJCZ004.
I keep DHCP enabled so that the provider can renumber IP addresses if they want; this also allows the service to come up after migration to a different location upon my request.
I shouldn't be guilty of "network abuse" if the provider sets improper DHCP lease duration which causes my OS to keep using an IP address that has been unassigned from my service.
So far, four providers renumbered IP address on my services: SecureDragon, AlphaRacks, WebHorizon, VirMach.
Among those, VirMach was the only provider that renumbered IP address without sending prior notice.
If they plan to do so regularly, I may need to setup more scripts to automatically adjust DNS records and such.
Mine is .232 and when its used some other server, route goes somewhere else than NYCB018 but its happening quite often
All labeling ever did for us is cause MORE problems so I stopped doing it.
Example A:
Example B:
Yeah, possibly IP conflict. Enabled protection on it. Reconfigure and try again. If it doesn't work, let me know. This could also potentially knock out the entire network for NYCB018 if we're extremely unlucky so I'll check back in 10 minutes.
Done and seems work atleast for now. Hopefully net uptime has now better stats, thanks!
With Virmach's recent experiences, seems like no braincells to rub together are needed in some of these companies. I hope he's planning on going back over updates like these and documenting them all to the DC. Or beating them with the paperwork and contracts until they have a braincell fire. Something.
I'd have been roasted over a firepit if i did any of the things he's had done / not done, let alone any combo of them from one DC alone.
If I wasn't Canadian and really not wanting to travel still, I'd say Virmach hire me and I'll just fly around the US going DC to DC as your remote hands for a while lol I've got a bunch of related knowledge, but even if I turned off my brain and just did exactly what was asked, it would be smoother for everyone
Wanted to ask what is wrong with FFME001 as my hetrixtools does not complain...


But then I tried to login as root and it did not allow me (???????????!?!?!? I know my password!)... so I decided to go to panel and I see it's dead (?)
What fucking vodoo magic is happening here?
Yeah, possibly IP conflict. > @cybertech said:
It's actually a pretty hilarious paradox. They keep raising the rates, reducing the level of service they provide, and I highly doubt it translates over to the hands getting paid much. From what I've seen they basically end up making around 10-20% of the hourly rate you get charged. To be fair though I also assume once you add in benefits, all the dead hours where they still need to be paid, and I'd imagine some level of liability insurance, or possibly sub-contracting, it probably somehow ends up leaving thin margins still.
The part I still don't understand though is the reduction of the level of service AND raising prices astronomically. Basically, at least one of the datacenters raised their rate by like let's say +50% and then they updated their guidelines to where within that timeframe you have to pay for, they'll only do a list of 5 different tasks and that's it. Tasks that definitely take way less than the hour minimum. So once you take that into account you might end up paying $100-200 for a button press and even then they still struggle to do it, so why not just hire more people if the demand is so high? It's not like they're hiring experienced people anyway if they're also unable to do anything above a button press.
Haven't been able to look into that one, I've been putting it off/lower on the priority list because I noticed the same thing, it only appears to be a panel issue. It could be the following:
It didn't help, network still going up'n'down
Message me the IP, I want to make sure it's not a node-wide issue.
@VirMach i cannot access service details page of my vps since a week now i always get timed out errors i forgot the new ip and just want to see the ip address of my vps if that's still active what to do?, Also is there any way to reset/check my username so that I can see if ip address there , i always accessed pannel from services detail page which auto logged me in so don't know my user name please help
Want free vps ? https://microlxc.net
Done, not sure tho if its nodewide since it seems to go to different node when its not working on my server